MaD allows for simple and intuitive design of continuous sonic gestural interaction. The motion-sound mapping is automatically learned by the system when movement and sound examples are jointly recorded. In particular, our applications focus on using vocal sounds – recorded while performing action, – as primary material for interaction design. The system integrates of specific probabilistic models with hybrid sound synthesis models. Importantly, the system is independent to the type of motion/gesture sensing devices, and can directly accommodate the use different sensors such as, cameras, contact microphones, and inertial measurement units. The application concerns performing arts, gaming but also medical applications such auditory-aided rehabilitation.
MaD has been demonstrated at SIGGRAPH’14 Studio & Emerging Technologies, by Jules Françoise, Frédéric Bevilacqua, Riccardo Borghesi and Norbert Schnell. Many thanks to Omid Alemi and Maria Fedorova for their essential help during the conference.
Our presentation at SIGGRAPH’14 was composed of two installations. On the Studio side, we demonstrated a system for crafting gesture control strategies for sound textures. On the Emerging Technologies side, we proposed an imitation game inviting participants to link vocalizations to their gestures.

The system implements an approach of Mapping-by-Demonstration that allows novice users to craft gesture control strategies intuitively. The process is simple: listen, move, and the system learns the relationship between your hand gestures and the timbral variations of the sound. Then, you just have to move to explore a sonic environment.
The system uses Gaussian Mixture Regression (GMR) to map between hand movements, captured using the Leap Motion, and descriptor-driven corpus-based concatenative sound synthesis using CataRT by Mubu. During demonstration, the gesture must be performed with a single hand. We record synchronously the streams of motion features and sound descriptors to train a GMR that encodes the mapping. For performance, the mapping can be assigned to each or both hands. The movements can be used to explore the sound textures according to the given relationship, using the GMR that generates the associated trajectories of sound descriptors. Several gestures can be combined, superimposed, or recognized to create a complete sonic environment controlled with the hands.
The system has been demonstrated at SIGGRAPH’14 Studio & Emerging Technologies, by Jules Françoise, Frédéric Bevilacqua, Riccardo Borghesi and Norbert Schnell. Many thanks to Omid Alemi and Maria Fedorova for their essential help during the conference. Sound corpora were design by Roland Cahen for DIRTI — Dirty Tangible Interface by Matthieu Savary, Florence Massin and Denis Pellerin (User Studio); Diemo Schwarz (Ircam); and Roland Cahen (ENSCI–Les Ateliers).
[Could not find the bibliography file(s)
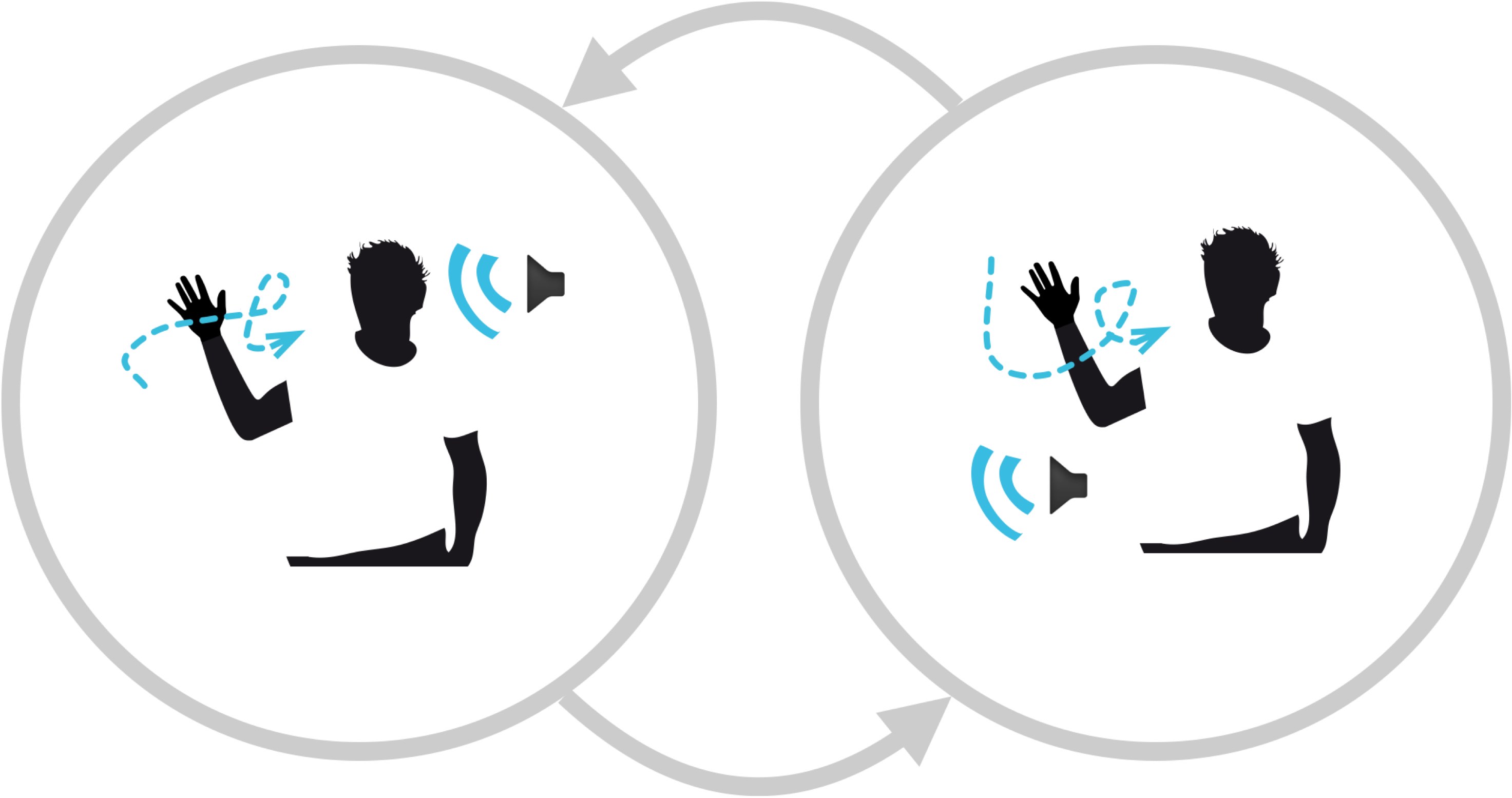
For SIGGRAPH’14 Emerging Technologies [?], we created an imitation game allowing users to link vocalizations to their gestures. The first step is to record a vocal imitation along with a particular gesture. Once recorded, the systems learns the mapping between the gesture and the vocal sound, allowing users to synthesize the vocal sounds from new movements. In the game, each player can record several vocal and gestural imitations, the goal is then to mimic the other player as precisely as possible to win the game!
The system is based on Hidden Markov Regression (HMR) [?] to learn the mapping between sequences of motion features and sequences of sound descriptors representing the vocal sounds — for example, MFCCs. During the demonstration phase, the user produces a vocalization synchronously with a gesture. The joint recording of motion and sound features is used to train a multimodal HMM encoding their relationships. For performance, we use HMR to continuously generate the sequences of sound descriptors associated to a new movement sequence, that drive the synthesis of the vocal sounds using descriptor-driven granular synthesis.








CataRT, mad, mapping by demonstration, MO, mubu, XMM