We just released the beta version of mubu.*mm, a set of objects for probabilistic modeling of motion and sound relationships.
Designing the relationships between motion and sound is a crucial aspect of the creation of interactive sonic systems. In this context, Machine Learning has proved to be an efficient design support tool, allowing users to easily build, evaluate and refine gesture recognizers, movement-sound mappings and control strategies.
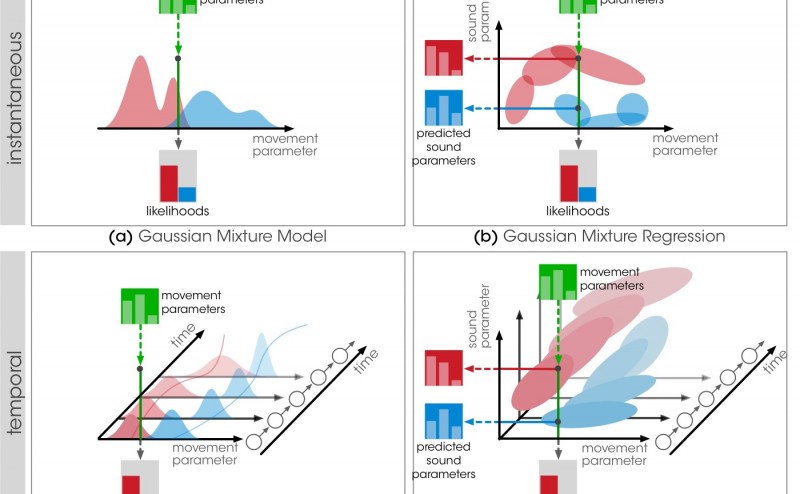
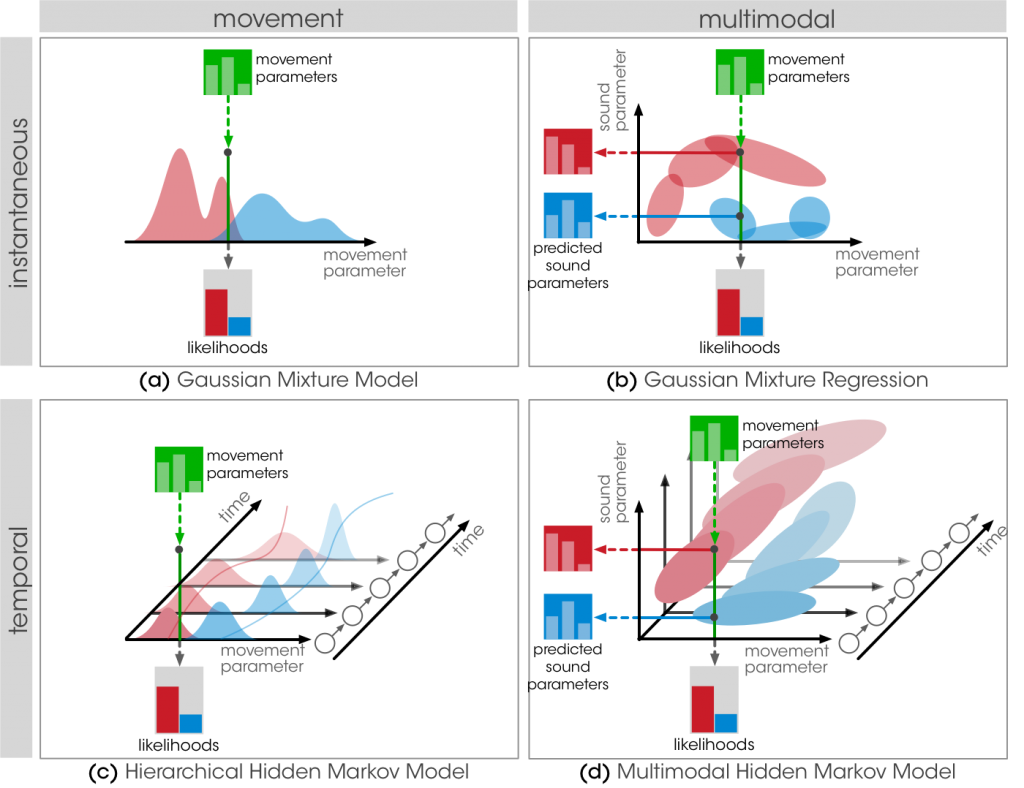
This collection of objects provides a set of tools for building mappings interactively. We propose 4 probabilistic models with complementary properties in terms of multimodality and temporality. We believe that a clear definition and understanding of these properties is crucial to design interactions efficiently.
We define 2 criteria for understanding the models’ properties: multimodality and temporality.
Multimodality: Movement models provide a statistical modeling of the input modality only. They allow for gesture classification, recognition and following. Multimodal models provide a joint representation of motion and sound parameter streams, and are therefore adapted to learning continuous motion-sound mappings.
Temporality: Instantaneous models implement a direct relationship between motion and sound features, meaning that the output of the model only depends on the instantaneous motion features. At the contrary, temporal models take into account the temporal evolution of movement parameters. As a result, the output of the model is dependent on the entire history of the input, which is typically important for dynamic gesture recognition.
We propose 4 models that intersect these criteria: Gaussian Mixture Models (mubu.gmm), Gaussian Mixture Regression (mubu.gmr), Hierarchical Hidden Markov Models (mubu.hhmm), and Hierarchical Multimodal Hidden Markov Models (mubu.xmm).
The models are implemented in an Interactive workflow in the Max programming environment. The implementation is extensively based on MuBu, a multimodal data container used to build, visualize and annotate the training data (see screenshots). The models are designed for a performance use, where the output parameters of the models are continuously updated, allowing continuous real-time recognition and mapping.
The models are part the the MuBu distribution, freely available on Ircam Forumnet. Note that the models have been released as a beta version! Please provide feedback, bug reports and feature requests on the MuBu user group.
This work has been presented at NIME 2014. Download the slides here.








featured, machine learning, mubu, XMM